Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
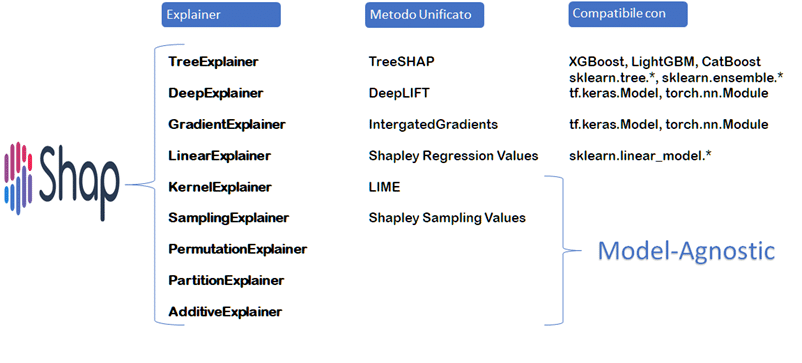
Shapley Additive exPlanations (SHAP) è un metodo di interpretazione model agnostic, il che significa che può essere applicato a qualsiasi modello machine learning. Per saperne di più guarda l’articolo Tecniche di Explainable Artificial Intelligence (XAI). Il metodo SHAP è inoltre in grado di fornire spiegazioni sia locali che globali. Gli Explainer di SHAP si consentono di capire come i singoli attributi influenzano la previsione del modello. Il metodo SHAP si basa sulla teoria dei giochi e sulla nozione di contributo marginale di un giocatore a una colazione di giocatori. Il risultato del metodo SHAP è una visualizzazione grafica dell’importanza delle variabili che rappresenta l’importanza di una variabile per la previsione del modello. A livello globale considera le medie di questi valori ottenuti.
Possiamo vedere un applicazione dello SHAP nei lavori “A Deep Learning Approach for Short Term Prediction” e “Predicting and Understanding Landslide Events With Explainable AI“. Nel primo caso per interpretare un modello CNN-LSTM di manutenzione predittiva e nel secondo caso per interpretare un modello XGBoost di previsione frane.
Ecco una panoramica dettagliata dei diversi explainer di SHAP:
È stato progettato per approssimare in modo efficiente i valori Shapley per modelli ad albero come XGBoost,, Random forest, Cart e i Decison trees. Poiché utilizza la funzione del valore atteso condizionale anziché il valore atteso ai margini può assegnare valori diversi da zero alle variabili non influenti, violando così la proprietà di Shapley dummy, questo ha delle conseguenze quando le variabili sono collineari.
NOTA: La proprietà di Shapley Dummy (teoria dei giochi) si riferisce alla situazione in cui un giocatore non partecipa alla cooperazione ma può comunque ricevere una ricompensa per la sua presenza. In base alla proprietà di Shapley dummy, la ricompensa totale che viene distribuita ai giocatori dovrebbe essere uguale alla somma dei loro contributi marginali alla cooperazione. In altre parole, il giocatore dummy (cioè colui che non partecipa alla cooperazione) non ha un contributo marginale alla cooperazione, e quindi non dovrebbe ricevere alcun pagamento. Questa proprietà è importante perché assicura che i giocatori ricevano una ricompensa equa in base alla loro effettiva contribuzione alla cooperazione senza che i pagamenti siano influenzati dalla presenza o dall’assenza di giocatori dummy.
Usa diversi metodi unificati, il principale è Expected Gradients una derivazione di Integrated Gradients e SmoothGrad. Come per DeepLift, Integrated Gradients funziona calcolando le differenze di input tra la baseline e il punto di input considerato. Queste differenze di input sono moltiplicate per il gradiente del modello rispetto all’input in quel punto. Questo processo si ripete a intervalli regolari lungo la linea retta tra il punto di partenza e il punto di input corrente. L’aria sotto la curva ottenuta da questi punti viene poi sommata per fornire una stima dell’importanza relativa ad ogni variabile di input. La libreria SHAP utilizza un concetto simile chiamato Expected Gradients che riformula l’integrale come un’aspettativa.
È un explainer molto semplice limitato al concetto supervisionato e ai modelli lineari di scikit-learn. Il Linear Explainer di Shap utilizza una formula analitica per calcolare i contributi di Shapley. Questa formula si basa sulla decomposizione di Shapley, che suddivide il contributo di ciascuna variabile di input in un termine di “peso” e un termine di “discrepanza”, che misura l’effetto della variabilesulla predizione del modello.
È un metodo model-agnostic basato su LIME. Segue infatti le stesse fasi di LIME come l’inserimento dei modelli lineari ponderati ma utilizza le coalizioni di campioni Shapley e un Kernel diverso che restituisce i valori Shapley come coefficienti. Poiché sostituisce le variabili assenti alla cooperazione con dati casuali, ha problemi con le proprietà dummy e quindi con le variabili collineari.
È un metodo efficiente per calcolare i valori Shapley tramite l’utilizzo di un campionamento casuale di punti. È model-agnostic e presuppone l’indipendenza tra le variabili.
È il metodo più vicino all’approccio brute-force per l’approssimazione del valore di Shapley. Questo metodo funziona permutando tutte le variabili in entrambe le direzioni. Se viene eseguito una sola volta, restituisce i valori Shapley fino al secondo ordine, se eseguito più volte si ottiene maggiore fedeltà nei risultati.
NOTA: Per termine “brute-force” si indica quell’approccio computazionale in cui tutti i possibili risultati vengono esaminati esaustivamente senza l’utilizzo di algoritmi o euristiche che ne limitano l’analisi. Il costo computazionale di questo approccio è molto alto.
Calcola i valori Shapley su un albero che definisce una gerarchie di variabili. È consigliabile quando molti delle variabili appartengono allo stesso gruppo o categoria o quando le variabili sono fortemente correlate.
Approssima il modello ad un Additive Feature Attribution Model (AFAM). AFAM si utilizza per calcolare l’importanza delle variabili. È particolarmente utile per modelli di machine learning complessi come gli alberi decisionali o reti neurali in cui l’importanza delle variabili non è ovvia. È usato anche nel caso di variabili categoriche.
SHAP nel suo complesso è un metodo model-agnostic poiché tutti gli explainer possono coprire qualsiasi modello e casi d’suo. Inoltre qualsiasi explainer può essere inizializzato allo stesso modo e producono più o meno gli stessi grafici di output.
Per vedere dei tutorial cerca nella sezione XAI del nostro sito.


