Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

I sistemi di raccomandazione sono un importante classe di algoritmi machine learning che offrono “rilevanti” suggerimenti per gli utenti. Si distinguono in COLLABORATIVE FILTERING o CONTENT-BASED SYSTEM.
Come fa YouTube a suggerirti un video da vedere? Come fa Google a sapere a quali notizie sei interessato? Usano una tecnica di apprendimento automatico denominata Sistemi di raccomandazione.
In pratica, i sistemi di raccomandazione rappresentano una classe di tecniche e algoritmi che sono in grado di suggerire agli utenti elementi “pertinenti”. Idealmente, gli articoli suggeriti sono il più pertinenti possibile per l’utente, in modo che l’utente possa interagire con tali elementi: video di YouTube, articoli di notizie, prodotti online e così via.
Gli articoli sono classificati in base alla loro pertinenza e quelli più pertinenti vengono mostrati all’utente. La pertinenza è qualcosa che il sistema di raccomandazione deve determinare e si basa principalmente su dati storici. Se di recente hai guardato video di YouTube sui gatti, allora YouTube inizierà a mostrarti molti video di gatti con titoli e temi simili!
I sistemi di raccomandazione sono generalmente divisi in due categorie principali: filtraggio collaborativo (collaborative filtering) e sistemi basati sul contenuto (content-based systems).
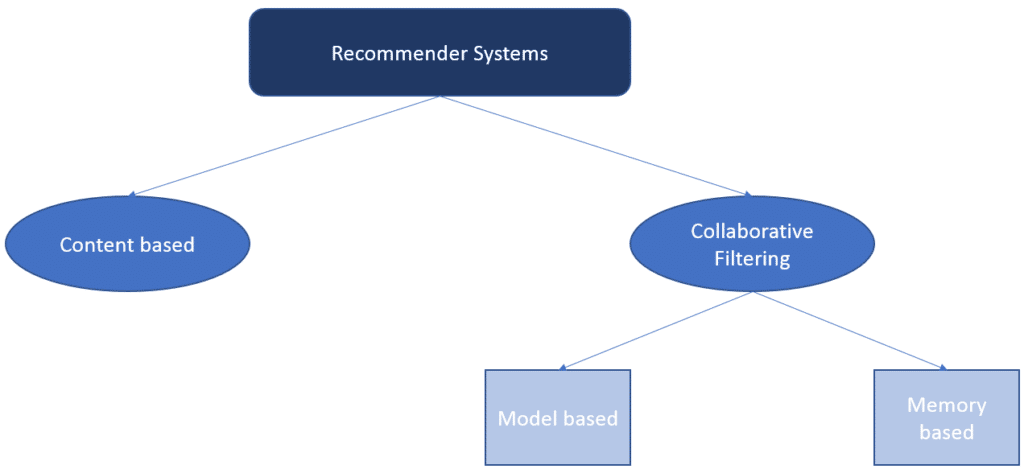
I metodi di filtraggio collaborativo per i sistemi di raccomandazione sono metodi che si basano esclusivamente sulle interazioni passate tra gli utenti e gli elementi di destinazione. Pertanto, l’input per un sistema di filtraggio collaborativo saranno tutti i dati storici delle interazioni dell’utente con gli elementi target. Questi dati sono in genere memorizzati in una matrice in cui le righe sono gli utenti e le colonne sono gli elementi.
L’idea alla base di tali sistemi è che i dati storici degli utenti dovrebbero essere sufficienti per fare una previsione. Ad esempio, non abbiamo bisogno di altro oltre ai dati storici, nessuna spinta aggiuntiva da parte dell’utente, nessuna informazione di tendenza attuale, ecc.

I metodi di filtraggio collaborativo sono ulteriormente suddivisi in due sottogruppi: metodi basati sulla memoria e metodi basati sul modello.
I metodi Memory-based solitamente prendono come input vari dati e calcolano le raccomandazioni sull’intero dataset delle persone usando metriche di similarità.
Gli approcci Model-based, costruiscono un modello partendo da un training-set e lo validano su dati di test. A differenza dei metodi Memory-based vengono considerati solo un sottoinsieme di utenti per costruire il modello.
Esempio Codice di Filtraggio collaborativo
Adesso creiamo un un sistema di raccomandazione di filtraggio collaborativo usando Graph Lab.
import graphlab
import pandas as pd
#1 Carichiamo I dati con pandas
r_cols = ['user_id', 'item', 'rating']
train_data_df = pd.read_csv('train_data.csv', sep='\t', names=r_cols)
test_data_df = pd.read_csv('test_data.csv', sep='\t', names=r_cols)
#2 Convertiamo il dataframes come graph lab SFrames
train_data = graphlab.SFrame(train_data_df)
test_data = graphlab.SFrame(test_data_df)
#3 Alleniamo il modello
collab_filter_model =
graphlab.item_similarity_recommender.create(train_data,
user_id='user_id',
item_id='item',
target='rating',
similarity_type='cosine')
#4 Generiamo le raccomandazioni
which_user_ids = [1, 2, 3, 4]
how_many_recommendations = 5
item_recomendation = collab_filter_model.recommend(users=which_user_ids,
k=how_many_recommendations)
Contrariamente al filtraggio collaborativo, gli approcci basati sul contenuto useranno informazioni aggiuntive sull’utente e/o sugli elementi per fare previsioni. Ad esempio, nella gif del filtraggio collaborativo, un sistema basato sul contenuto potrebbe considerare l’età, il sesso, l’occupazione e altri fattori personali dell’utente quando fa le previsioni. Quindi magari un video di moda femminile non interessa ad un maschio.

Quindi per il loro sistema di previsione si fanno uso dei dati del cliente come età, sesso etnia, preferenze, lavoro ecc.
Pertanto, i metodi basati sul contenuto sono più simili all’apprendimento automatico classico, nel senso che si sviluppano funzionalità basate sui dati degli utenti e degli articoli e li si usano per fare previsioni. Il nostro input di sistema è quindi le funzionalità dell’utente e le funzionalità dell’articolo. Quindi l’output del nostro sistema è la previsione se l’utente desidera o meno un articolo.
Esempio Codice di sistemi basati sul contenuto
Adesso creiamo un un sistema di raccomandazione basati sul contenuto usando Graph Lab.
import graphlab
import pandas as pd
#1 Carichiamo I dati con pandas
r_cols = ['user_id', 'item', 'rating']
train_data_df = pd.read_csv('train_data.csv', sep='\t', names=r_cols)
test_data_df = pd.read_csv('test_data.csv', sep='\t', names=r_cols)
#2 Convertiamo il dataframes come graph lab SFrames
train_data = graphlab.SFrame(train_data_df)
test_data = graphlab.SFrame(test_data_df)
#3 Alleniamo il modello
cotent_filter_model = graphlab.item_content_recommender.create(train_data,
user_id='user_id',
item_id='item', target='rating')
#4 Generiamo le raccomandazioni
which_user_ids = [1, 2, 3, 4]
how_many_recommendations = 5
item_recomendation = cotent_filter_model.recommend(users=which_user_ids,
k=how_many_recommendations)
Se ti è interessato l’articolo dai un occhiata al nostro blog.


