Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

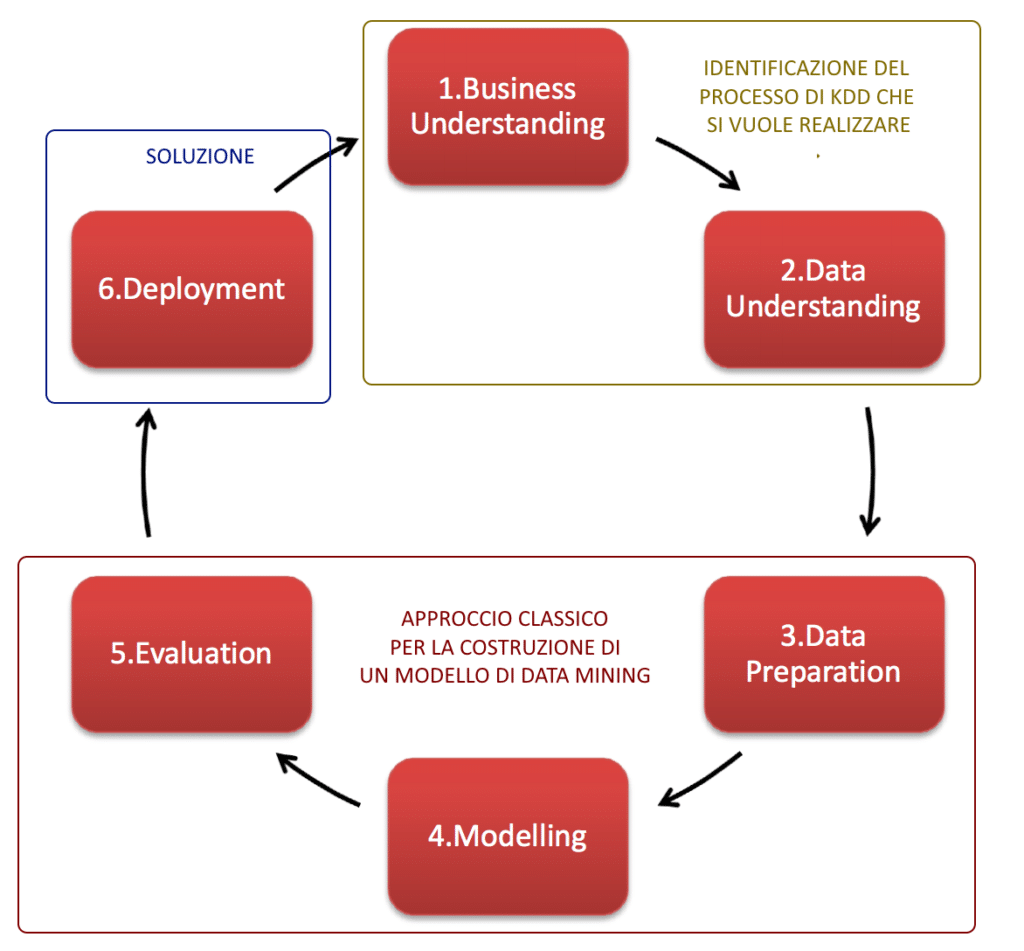
CRISP-DM è l’acronimo di Cross-Industry Standard Process for Data Mining, un metodo di comprovata efficacia per l’esecuzione di operazioni di data mining.
Il modello CRISP-DM è un prodotto neutrale definito da un consorzio di numerose società per la standardizzazione del processo di Knowledge Discovery in Databases (KDD)
Il processo/metodologia di CRISP-DM si identifica in questi sei passaggi principali:
Viene definito il problema di data mining da risolvere. Si concentra sulla comprensione degli obiettivi e dei requisiti del progetto da una prospettiva di business. Importante in questa fase stabilire i criteri per determinare l’esito del data mining dal punto di vista aziendale.
L’obiettivo è la raccolta dei dati e la formulazione di ipotesi. Infatti si inizia con una raccolta di dati e procedere con le attività al fine di acquisire familiarità con i dati, identificare problemi di qualità dei dati, scoprire le prime informazioni sui dati o rilevare sottoinsiemi interessanti per formulare ipotesi di informazioni nascoste.
Inoltre bisogna distinguere i dati in
• Dati Esistenti: dati transazionali, sondaggi, registri ecc. Importante è stabilire se sono sufficienti a soddisfare gli obiettivi.
• Dati acquisiti: capire se l’azienda utilizza dati supplementari (esempio dati demografici) e stabilire la necessità per gli obiettivi.
• Dati aggiuntivi: capire le sorgenti di acquisizione soddisfano le nostre esigenze oppure è necessario acquisirne altri.
Infine bisogna identificare i dati più promettenti, quali sono irrilevanti e da quale sorgenti provengono e stabilire le caratteristiche chiave dei dati: Quantità – Tipologia – Codifica
La fase di preparazione dei dati indica tutte quelle attività utili a preparare l’insieme dei dati finale partendo dai dati iniziali. È uno degli aspetti che richiede più tempo nel progetto. Questa fase implica operazioni come aggregazione di record, selezioni di sottoinsieme di dati, ordinamento dei dati, unione di record, sostituzione o rimozione di valori vuoti e suddivisione di insieme di dati di addestramento e dati di test.
In questa fase di scelgono e vengono applicate le tecniche di data mining. La modellazione viene in genere eseguita in più azioni. Si eseguono diversi modelli utilizzando i parametri di default, per poi regolare i parametri. Spesso per avere una risposta soddisfacente bisogna tornare alla fase di preparazione dei dati. In questa fase avremo i primi risultati che ci permettono di valutare i modelli.
Tramite l’analisi dei risultati si valuta se sono stati raggiunti gli obiettivi prefissati e si ipotizza una futura applicazione del modello. Il risultato finale è la scelta dei modelli migliori. Nella valutazione del progetto occorre includere i responsabili delle decisioni chiave che hanno portato a questo risultato.
L’implementazione è il processo che consente di utilizzare i risultati acquisiti per apportare miglioramenti al business. Questo significa implementare una rappresentazione “in codice” del modello per acquisire nuovi dati, per creare un meccanismo che permetta l’utilizzo di nuove informazioni e risolvere il problema aziendale originale. È importante nella rappresentazione “in codice”, includere anche la preparazione dei dati usata per la modellizzazione.
In questo articolo ho voluto fornirvi una breve descrizione della metodologia CRISP-DM. Comunque ci sono numerose guide per dettagliare ogni fase sopra descritta. Nel blog parleremo di alcuni casi studi e come abbiamo applicato il metodo nei nostri casi.
Seguici sul nostro blog per maggiori informazioni
Immagine di rawpixel.com su Freepik


